

Don’t be afraid of anti-patterns
Everyone knows that database integration is a bad thing. And everyone knows that it is an anti-pattern you should avoid by any means. The standard rule is that services shouldn’t integrate using a database as a connection point (even though sometimes it happens anyway). Well, we all know that following best practices is important. But unfortunately, we often tend to forget the real reasons why they are so good. In some situations, these reasons aren’t applicable.
In fact, sometimes you can use DB for integration, provided certain conditions are met. Let’s look at a case when database integration works much better than a classic microservice approach.
Problem statement
We will go straight to the use case and suggest we have a typical service that controls some data stored in DB and provides public API to CRUD the data via HTTP (data API further in the text). And we have a task to make some calculations based on this data periodically. Let’s say it is a periodic job we want to execute once an hour. This job is CPU-bound because we intend to do heavy calculations on large amounts of data by the number of records and fields involved. Although that could be the case for many things — validations, checksums, hashing, aggregations, statistics — we will take the calculation of aggregates as an example.
Straightforward design options and their shortcomings
All-in-one service
Ok, the first and most obvious solution that comes to mind is to gather both business and aggregation logic in one service. We will call it Data service. As for aggregation logic, we will need to schedule a job, or it will wait in an idle state for the start time. Data service connects to Data DB and consists of a data API implemented by business logic, aggregation job, and aggregation API (see Design 1). Main business logic is responsible for processing user requests, handling original data, and updating tables using the received information. Aggregation job is executed periodically. It reads all original data required for calculations, generates aggregates, and writes them to a separate table in the same Data DB.
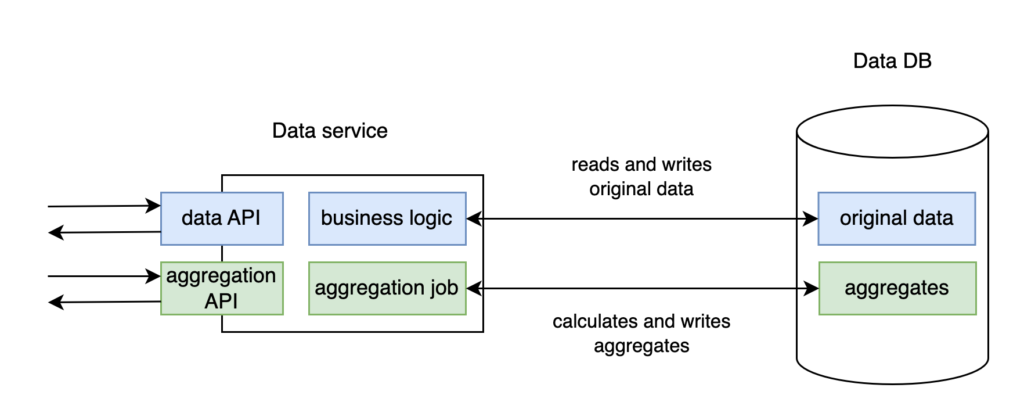
Unfortunately, this solution has problems. Due to heavy calculations and a lot of processor capacity required, the nature of our aggregation task is very different from the usual processing of API requests. It turns out to be a bad idea because this way a CPU-bound task will consume all available resources, and users will experience delays and timeouts on their requests to our service.
You can try to launch additional or bigger instances to solve the issue, but it won’t help. The heavy task will consume all resources anyway, and we won’t have anything left to process our API requests. Even though we will calculate our background job faster, the latency issues with request processing will stay. And we aim to fix these issues, not speed up the job. It won’t give us anything. Also, this will result in cloud resources overbooking. It’s not a pleasant outcome, so let’s not do this.
True microservices
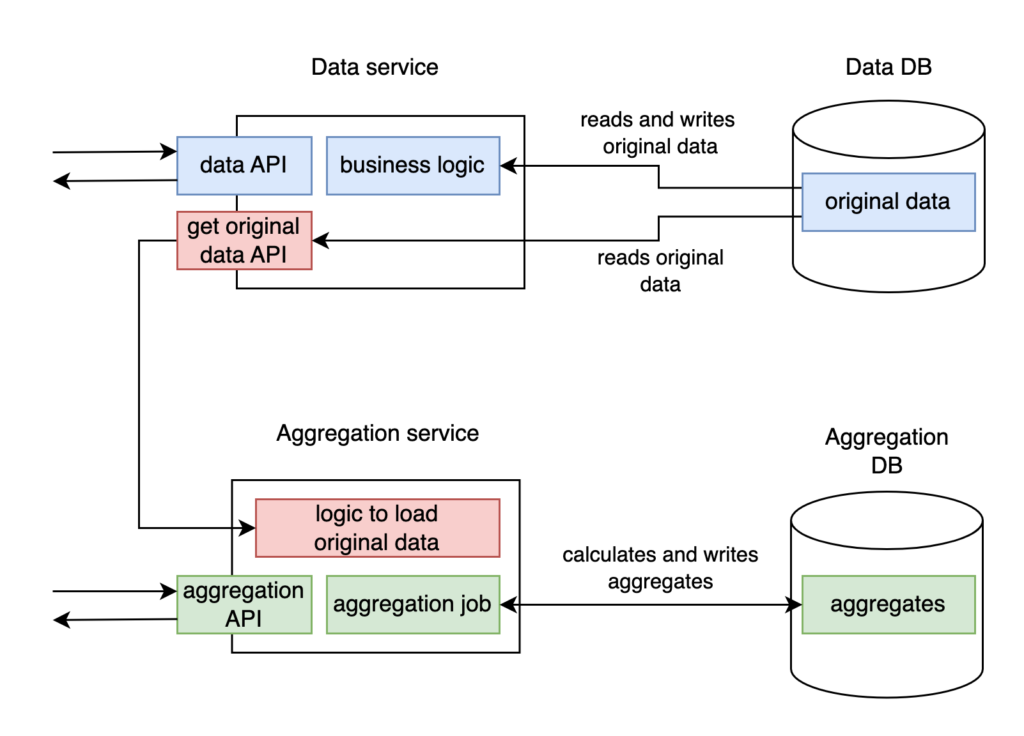
No big deal. Another great idea, then! The answer is straightforward. If a single service containing all the logic doesn’t work well, let’s do it in a true microservice way. We will do it nicely. Data service will work with original data and separate Aggregation service will produce aggregates. Each will work with its own isolated DB: Data service will store the data in Data DB, and Aggregation service will write aggregates to Aggregation DB. No service will interact directly with other service’s database. We will build a specific endpoint to fetch original data from DB in Data service.
However, it could be better again. Although everything looks good and classy at first glance (see Design 2), this system design has two major problems. The data consumption pattern of aggregation job differs greatly from that of all other Data service consumers. It requires a lot of data. So, we must unload almost all original data from Data service to Aggregation service. Firstly, we have a lot of extra work to build an additional API in Data service to provide original data and another API in Aggregation service to consume that data. Secondly, we need to transfer a large volume of data between two services, which will require a lot of resources — CPU and network capacity. And, in the end, data transfer will simply take a lot of time.
But that’s not all. Another problem is that we need to implement a new endpoint on Aggregation service side to provide aggregated data to consumers. It means that all consumers now need to integrate with two services instead of one.
Design 2 represents the resulting solution. Data service will have to provide API to get original data in addition to data API. On Aggregation service side, aggregation API will be implemented together with the background aggregation job, plus a new logic to load the original data. Aggregation job will do its work and store produced aggregates in a separate table in Aggregation DB.
The plot thickens: it looks even worse when we try to fix it
And now it starts getting tricky. It seems that the two most obvious solutions don’t work. Even the mighty microservices don’t help. But what can we do to improve the solution if, in this particular case, separation into microservices brings so significant cons? Can we avoid all these issues?
Yes, we can. We can create two services using DB as an integration point instead of transferring a large amount of data between two services and, therefore, between two databases. Namely, implement a famous anti-pattern. That is represented in Design 3. Here, Data service connects to its dedicated Data DB and implements data API and main business logic. At the same time, Aggregation service provides API to the clients, executes the job, and stores generated aggregates to DB. Aggregation service makes all the calls to Data DB directly and doesn’t need any endpoint to access the data. As a result, Data DB stores all original data, and Aggregation DB only aggregates.
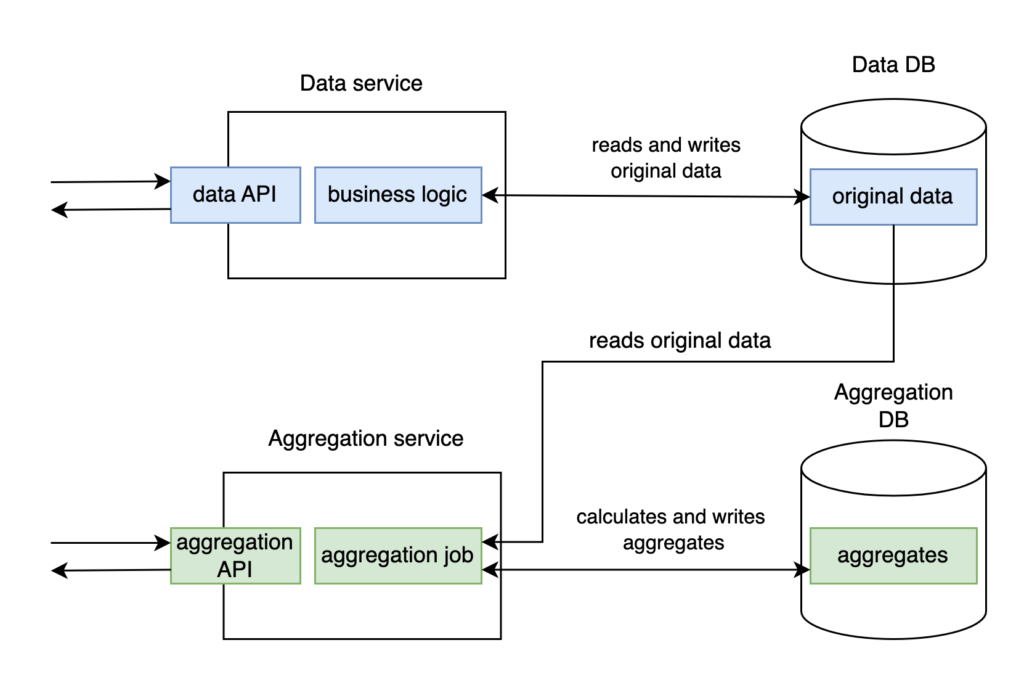
Even though this solution helps to prevent transferring enormous amounts of data between services, it is undoubtedly a database integration. And, of course, it became an anti-pattern for many reasons. Let’s refresh them briefly.
Issue #1. We don’t know who our clients are and have no idea what they do because we don’t have a dedicated API to separate our service’s internal data structures. Therefore, we don’t have any control over which data the clients consume. Hence, we lose the critical ability to change the internal structure whenever we need refactoring, system design improvements, or adding new features.
In fact, this is true only when, by database integration, we suppose that the internal structure of our data is exposed. And that is usually implied by default. However, there are mechanisms to create an API in DB via SQL views and access rights. It’s more complicated than to create an API over HTTP. But the real reason is that application developers are usually not experts in the intricacies of setting DB access rights. Even though such an API is not the best decision and has some drawbacks, it is a much better solution than opening your system’s internals to all its clients.
But we won’t dive deeper into how to do it now. Unfortunately, developers usually neither create an API layer nor adjust it for user access when implementing database integration. And this is the real anti-pattern.
Issue #2. Schema migrations are complex. Sometimes, we don’t know our clients (this follows from the previous point). And if we don’t know them, how can we notify all consumers about the subsequent changes? So that they will update their code in advance? Anyway, even if we know all our clients, it might be challenging to agree on changes in the schema between all the teams involved. And it’s tough to create a new version of API, unlike with application API. Changes that are improvements for original Data service or one of its consumers, can cause issues with the code of other consumers. So, negotiations between teams require a lot of time.
Issue #3. Changing DB technology to fit your service’s needs or your team’s preferences is impossible. And if you agree to change it, everyone needs to change it, as the integration database links everyone together.
Fine, after we have gone through the cons of database integration, it is time to take the next step to simplify Design 3. Despite its benefits for data distribution, it makes API more complex for the clients as they are now located in different services. But there is no reason to keep the aggregation API in Aggregation service, even though we moved aggregation job there due to its background nature. We can make life easier for our clients and move it to Data service, which is already a public network service. This way, users will need to integrate with only one service. If aggregation API is located in Data service, storing the aggregates in Data DB is very reasonable. After the changes, we get Design 4. There is only one database via which all interactions between two services happen, and Aggregation service contains only aggregation job.
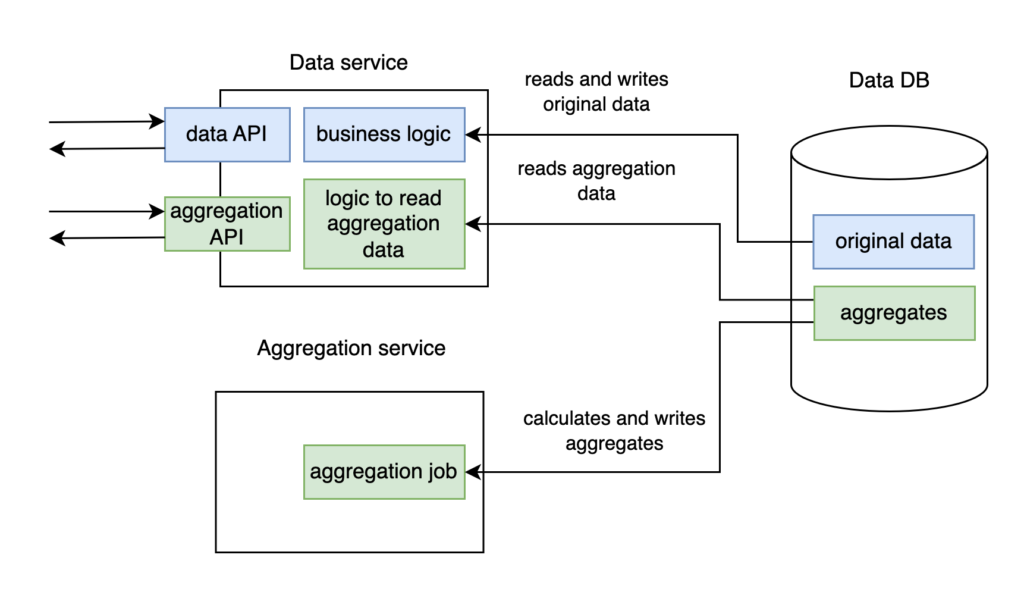
But… this is an even scarier version of “Database integration”! The coupling between services became even tighter. Now, Aggregation service not only reads from Data service DB but also writes there! It’s a mind blow during refactoring. As a developer, you’re trying to find the code in Data service that changes its data, but you can’t. It’s not there. Later, it turns out to be in another service. Another service touches the data with its “dirty hands”! This is a complete violation of loose coupling principles between two systems. That’s bad.
A knight’s move: two services become one
Can we turn the situation around? Can we escape this vicious circle and find a great solution that possesses all the pros of Design 4 but not its cons?
In fact, we can make a knight’s move and mitigate the cons of database integration. We will join the code of both Data and Aggregation services in one repository and take out their DAO code into a separate library shared between them. The shared DAO module will contain migrations with DB schemas, entities (data structures), repositories, and connection settings. Because we share DAO module on the code level, we guarantee that it will always be the same in the two services, and any significant change in it will be supported in both. Otherwise, the build will be broken. Also, we will configure our build to generate two artifacts (previously two services) to be deployed simultaneously.
In the article’s subsequent text, we will refer to the modules with deployment artifacts as applications (apps). This will help differentiate between a service with its own release cycle and a module with a deployment artifact.
Finally, we receive Design 5, where our two services become single with two applications connected via DB. The library module is used to get access to this DB. Aggregation app has become very simple and only has code related to aggregation and saving results.
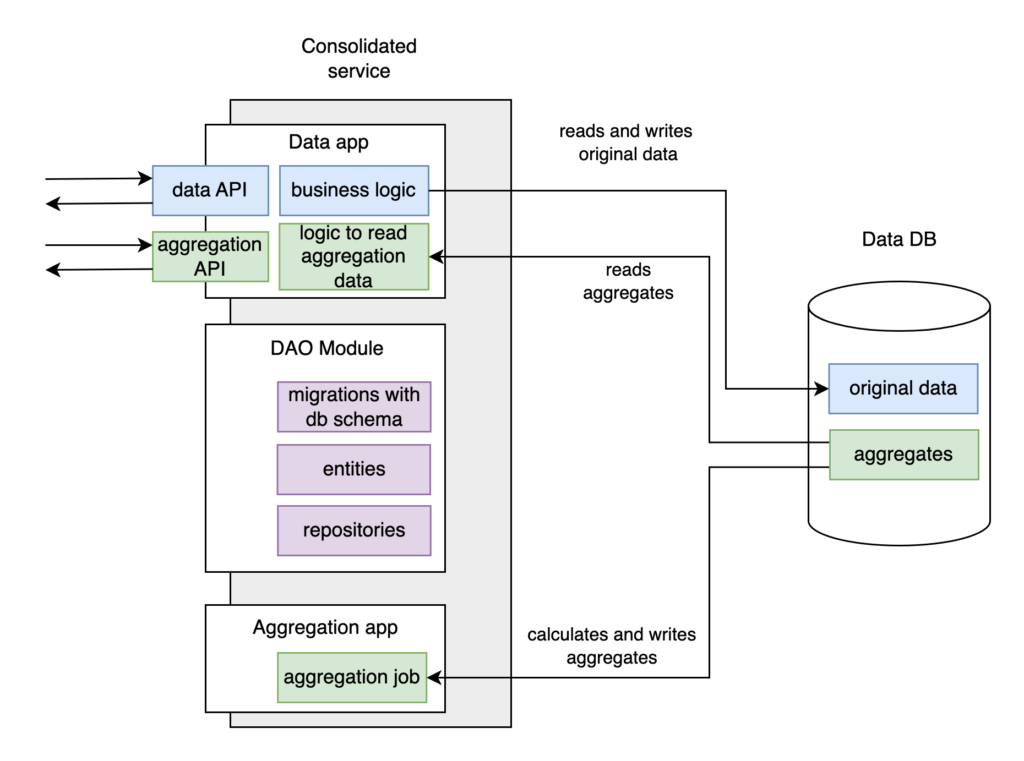
A critical condition for that scheme is that the two applications and DAO module must be developed and supported by one team and live in one repository. They must be versioned, released, and deployed together. That is the crucial difference from the services, which are often supported by separate teams and have their own release cycles.
Surprisingly, a service consisting of a few modules is a well-known and typical setup for many systems. And that is precisely the design we suggest as a solution to the problem at hand.
Database integration wins
But what was gained by this tricky move? Database integration is still there. Yes, we have a solution with a few modules integrated by DB. But wait with throwing stones at us a little bit. First, let’s return to the issues created by DB as a connection point and check them in our new design.
Issue #1. Generally, database integration results in extreme complexity when changing the internal structures of tables.
But here, we have no external consumers. Aggregation app is the only consumer of original data, and it connects to DB only via DAO library. Our solution implies that all possible consumers of original data can access it only via DAO module. Suddenly, critical issue #1 is no longer valid for our case.
Issue #2. Generally, database integration leads to very complex migrations.
Well, that’s also not true for our new solution. The strict synchronization of versions solves that. If we need to add a new migration in one application, we will implement it in DAO module, and it will automatically appear in the second application. This means we can ensure the DB schema is constantly updated to the latest version. If one module changes the schema, the second module will continue working correctly because we need to make any changes backward compatible to support rolling updates anyway (we suppose there are few instances of any service or application).
For example, we have two instances of a service, and we launch one with a new version and one with an old one. At the same time, the DB was already upgraded to the latest version, and the old-version instance works fine with it because, again, we must design any service to support backward-compatible schema migrations.
Issue #3. It is impossible to change DB technology individually for each service.
It is obvious now that this issue does not apply to our multimodule service as we have only one service consisting of a few components. Thus, we can change DB technology for the entire service. We do not intend to use one technology for one application and another for the second. It’s also outside our plans to grow our service to contain many applications. And given the limited number of modules and the condition that all of them are supported by the same team, that issue isn’t a problem here. We will change the technology for all modules or leave it as it is.
Suddenly, after reviewing the initial issues, we discovered that we had addressed all of them in our module design. This is great, but there is more to come. Now, it’s time to consider the pros.
To start with, we save an enormous amount of time and effort because we don’t need to implement additional API and transfer all the data from one service to another. We also save on our decision to move aggregation API to Data app. Otherwise, we’d need to implement all endpoints, configuration, and security in a new application. And doing it from scratch requires a lot of work and a significant amount of code. Yet we already have Data app where all this is done for Data API, and we just reuse it.
Saving cloud resources is another advantage that might be even more impactful. As mentioned earlier, the aggregation job is a CPU-bound, heavy task. And we need powerful and expensive instances to run it. If we place API in the same application, we must keep these instances constantly running. Not all the instances, as it’s possible to scale them. But some percentage of containers should be up. However, without API, the app becomes just a job that can be executed on schedule. All the instances can be stopped after the calculations have been executed. At the same time, Data app (with all endpoints) always works and doesn’t use a lot of resources. So, Design 5 provides a much more efficient consumption of cloud resources. And if we consume fewer resources, it costs us less money. This is a significant pro.
So, we could implement everything very conventionally via two separate microservices and spend a lot of effort and resources on transferring data from one microservice to another. And all that only in order to do it as expected. However, we decided to think deeper and develop a better way to integrate the services (now the two components of one service). Using an approach that seemed illicit at the beginning.
Any best practice has its limitations
After careful examination of all the cons of database integration, we found a working solution for some, while others turned out not to play a role in our setup. As the database doesn’t play the role of a public API here, localizing access to it in the code and creating an abstraction layer is possible. We achieved this by developing a shared library to share schema changes between the two modules. As for the remaining issues, they are relevant only for cross-team communications. They aren’t applicable in our case because the project scope is not extensive, and we intend all modules to be supported by one team.
Overall, in this particular situation, database integration fits very well and has a lot of benefits over the microservice approach. It’s easier to develop, easier to maintain and cheaper to run. Of course, it’s not the only possible case. You can come up with others. The main thing is not to wave away a potential solution only because it is not a best practice.
Like with everything in life, there is no silver bullet. Each best practice solves some particular problems and has its area of applicability. In this case, creating microservices, even services, and building HTTP API brings more troubles than advantages. Instead, we take another practice that is recommended to avoid any possible way. We take it and pay attention to why it is considered so bad. We address some of its downsides, and others turn out to be irrelevant to this particular solution. As a result, we can now easily use this pattern, and it works wonderfully for our purposes.